Video-to-4D Generation
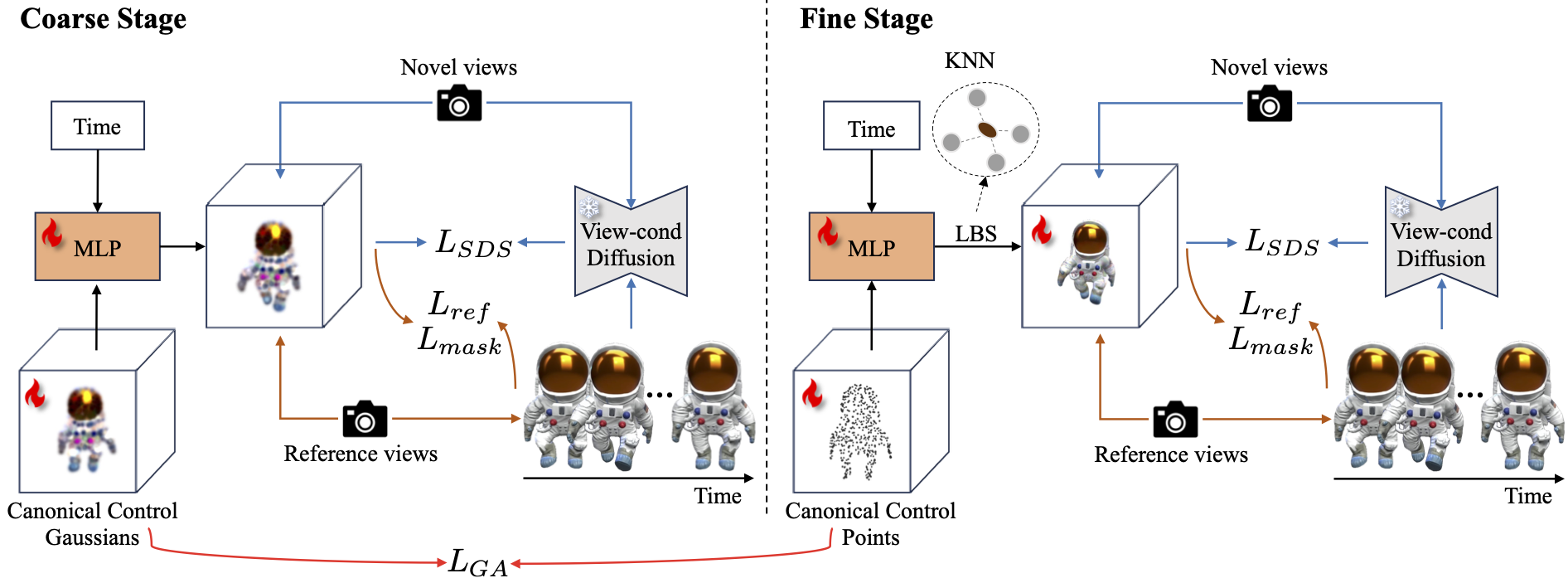
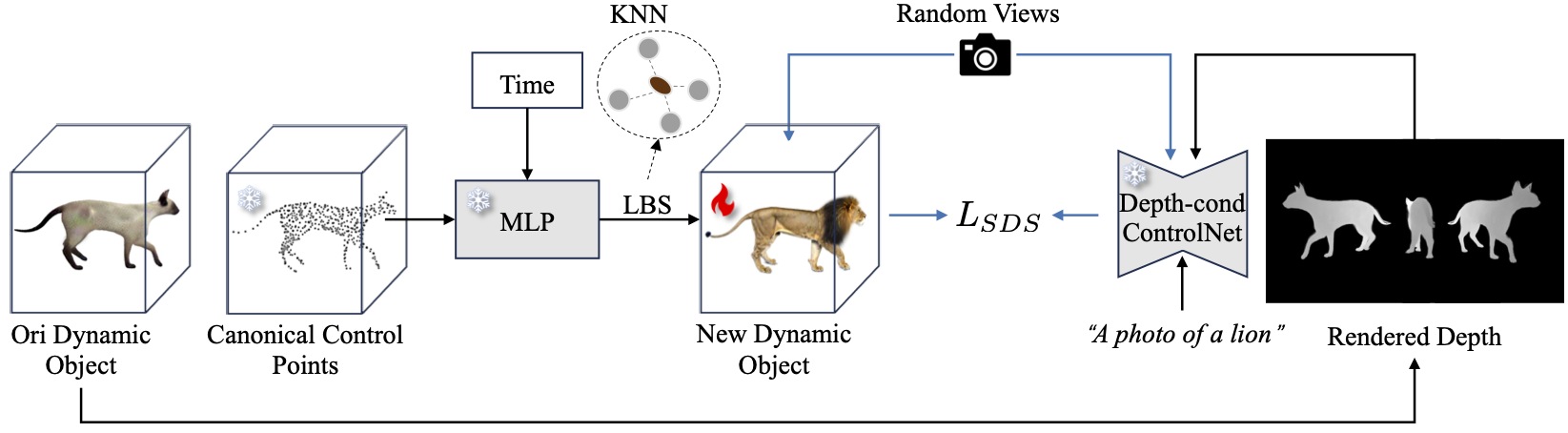
Given a single-view reference video, video-to-4D methods aim to recover a plausible dynamic 3D object that aligns with the video source. In this work, we propose a two-stage video-to-4D framework based on sparse control points, named SC4D, which utilizes separated modeling of appearance and motion to yield superior outcomes. In the coarse stage, we initialize control points as sphere Gaussians and learn a deformation MLP to predict the movements of these control points. Then in the fine stage, we utilize these control points to drive dense Gaussians in the LBS manner, and jointly optimize the appearance and motion together to obtain the final dynamic object. To ensure the fidelity of learned shape and motion in the fine stage, we introduce Adaptive Gaussian (AG) initialization based on control points, and Gaussian Alignment (GA) loss as an additional constraint.